MAC OS X 背后的故事-读书笔记
2019-05-16
[TOC]
可视化编程
Xcode 3 以前,Interface Builder 使用一种名为 nib 格式的二进制文件格式。不过由于 nib 不能用肉眼读,也不方便使用版本管理工具来管理,所以 Xcode 3 开始新加入一种名为 xib 的文本文件格式,最后再在项目编译阶段输出为 nib 格式。和产生静态界面布局代码的工具(如 MSVC、QtDesigner、 Delphi 等类似的软件)很不同,nib 是不被转译成相应 Objective-C 代码的。用户程序执行时,nib 文件被读入,解包,并且唤醒【注:awake,即载入 nib 会自动调用程序中 awakeFromNib 方法】,所以 nib 文件是在运行时动态加载的。
Objective-C 内存管理
在 2011 年 WWDC(苹果全球开发者大会)的一场与 Objective-C 相关的讲座上,开发者的人生观被颠覆了。
作为一个开发者,管理好自己程序所使用的内存是天经地义的事,好比人们在溜狗时必须清理狗的排泄物一样(美国随处可见“Clean up after your dogs”的标志)。在本科阶段上 C 语言的课程时,教授们会向学生反复强调:如果使用 malloc 函数申请了一块内存,使用完后必须再使用 free 函数把申请的内存还给系统——如果不还,会造成“内存泄漏”的结果。这对于 Hello World 可能还不算严重,但对于庞大的程序或是长时间运行的服务器程序,泄内存是致命的。如果没记住,自己还清理了两次,造成的结果则严重得多——直接导致程序崩溃。
Objective-C 有类似 malloc/free 的对子,叫 alloc/dealloc,这种原始的方式如同管理C内存一样困难。所以 Objective-C 中的内存管理又增加了“引用计数”的方法,也就是如果一个物件被别的物件引用一次,则引用计数加一;如果不再被该物件引用,则引用计数减一;当引用计数减至零时,则系统自动清掉该物件所占的内存。具体来说,如果我们有一个字符串,当建立时,需要使用 alloc 方法来申请内存,引用计数则变成了一;然后被其他物件引用时,需要用 retain 方法去增加它的引用计数,变成二。当它和刚才引用的物件脱离关联时,需使 release 方法减少引用计数,又变回了一;最后,使用完这个字符串时,再用 release 方法减少其引用计数,这时,运行库发现其引用计数变为零了,则回收走它的内存。这是手动的方式。
这种方式自然很麻烦,所以又设计出一种叫做 autorelease 的机制(不是类似 Java 的自动垃圾回收)。在 Objective-C 中,设计了一个叫做 NSAutoReleasePool 的池,当开发者需要完成一个任务时(比如每开启一个线程,或者开始一个函数),可以手动创立一个这样的池子, 然后通过显式声明把物件扔进自动回收池中。NSAutoReleasePool 内有一个数组来保存声明为 autorelease 的所有对象。如果一个对象声明为 autorelease,则会自动加到池子里。如果完成了一个任务(结束线程了,或者退出那个函数),则开发者需对这个池子发送一个 drain 消息。这时,NSAutoReleasePool 会对池子中所有的物件发送 release 消息,把它们的引用计数都减一 ——这就好比游泳池关门时通知所有客人都“滚蛋”一样。所以开发者无需显式声明 release,所有的物件也会在池子清空时自动呼叫 release 函数,如果引用计数变成零了,系统才回收那块内存。所以这是个半自动、半手动的方式。
———《Mac OS X 背后的故事》
Objective-C 2.0及LLVM
在 2007 年 10.5 发布时,Objective-C 做出了有史以来最大的更新,最大的亮点是它的运行库 libobjc 2.0 正式支持自动垃圾回收,也就是由运行库在运行时随时侦测哪些物件需要被释放。听上去很不错,可惜使用这个技术的项目却少之又少。原因很简单,使用这个特性,会有很大的性能损失,使 Objective-C 的内存管理效率低得和 Java 一样,而且一旦有一个模块启用了这个特性,这个进程中所有的地方都要启用这个特性——因此如果你写了一个使用垃圾回收的库,那所有引用你库的程序就都得被迫使用垃圾回收。所以 Apple 自己也不使用这项技术,大量的第三方库也不使用它。
这个问题随 Apple 在移动市场的一炮走红而变得更加严峻。不过这次,Apple 和与会的开发者讲,他们找到了一个解决问题的终极方法,这个方法把从世界各地专程赶来聆听圣谕的开发者惊得目瞪口呆——你不用写任何内存管理代码,也不需要使用自动垃圾回收。因为我们的编译器已经学会了上面所介绍的内存管理规则,会自动在编译程序时把这些代码插进去。
这个编译器,一直是 Apple 公开的秘密——LLVM。说它公开,是因为它自始至终都是一个开源项目;而秘密,则是因为它从来没公开在 WWDC 的 Keynote 演讲上亮相过 。
优异的答卷——Clang
前文提到,Apple 吸收 Chris Lattner 的目的要比改进 GCC 代码优化宏大得多——GCC 系统庞大而笨重,而 Apple 大量使用的 Objective-C 在 GCC 中优先级很低。此外 GCC 作为一个纯粹的编译系统,与 IDE 配合得很差。加之许可证方面的要求,Apple 无法使用 LLVM 继续改进 GCC 的代码质量。于是,Apple 决定从零开始写 C、C++、Objective-C 语言的前端 Clang,完全替代掉 GCC。
正像名字所写的那样,Clang 只支持 C,C++和 Objective-C 三种C家族语言。2007年开始开发,C 编译器最早完成,而由于 Objective-C 相对简单,只是 C 语言的一个简单扩展,很多情况下甚至可以等价地改写为C语言对 Objective-C 运行库的函数调用,因此在 2009 年时,已经完全可以用于生产环境。C++ 的支持也热火朝天地进行着。
Clang 的加入代表着 LLVM 真正走向成熟和全能,Chris Lattner 以影响他最大的“龙书”封面【注:见 http://en.wikipedia.org/wiki/Dragon_Book_(computer_science)】为灵感,为项目选定了图标——一条张牙舞爪的飞龙
{kind=link}
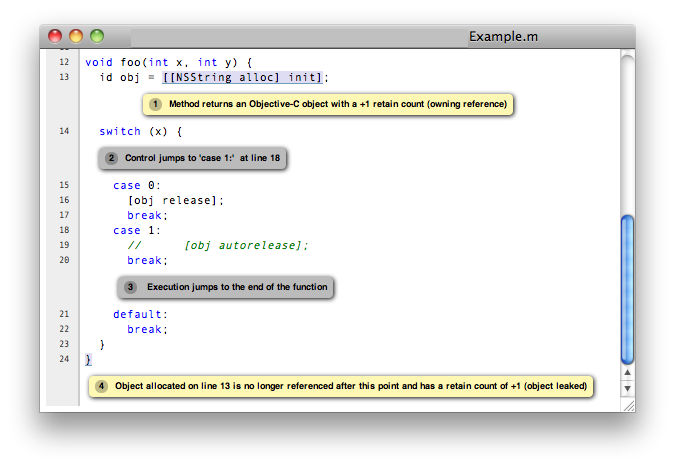
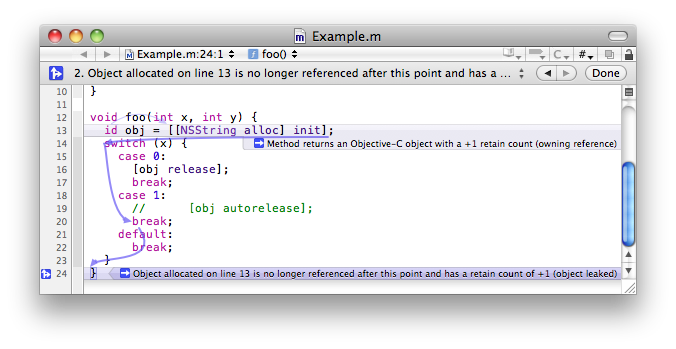
而 Clang 的一个重要衍生项目,则是静态分析工具,能够通过自动分折程序的逻辑,在编译时就找出程序可能的 bug。在 Mac OS X 10.6 时,静态分析被集成进 Xcode 3.2,帮助用户查找自己犯下的错误。其中一个功能,就是告诉用户内存管理的 Bug,比如 alloc 了一个物件却忘记使用 release 回收。这已经是一项很可怕的技术,而 Apple 自己一定使用它来发现并改正 Mac OS X 整个系统各层面的问题。但许多开发者还不满足——既然你能发现我漏写了 release,你为什么不能帮我自动加上呢?于是 ARC 被集成进 Clang,发生了文章开头开发者们的惊愕——从来没有人觉得这件事是可以做成的。
{kind=link}
{kind=link}
Cocoa
Cocoa 经过很长时间的发展,自然也保留了很多过时的 API 以保证和原先的产品兼容,而这次机会(全面支持64位架构)给苹果足够的理由彻底推翻原先的设计。在 Mac OS X 10.5 中, Objective-C 的运行库 libobjc 更新到 2.0,提供了全新的并发、异常处理、自动内存回收、属性(property)等新机制,其中很多新特性只供64位享用。同时,所有 int 都被改为 NSInteger,Core Graphics 中的 float 都改为 CGFloat,以保持 API 统一,这些都是 64 位架构上的改动。因此 64 位迁移给苹果一个很好的清理门户的机会。
作为相反的例子,这次清理也有不彻底的地方。比如从老版 Mac OS 中混进来的 Keychain 库,甚至具有 Pascal 风格的 API,由于没有替代品,它也得到了 64 位的更新。所以类似 keychain 这样的库成了现在 Mac OS X 程序员的噩梦。我每次用到 Keychain 都有痛不欲生的感觉。
-
- *经过 6 年时间,4 个发行版,苹果终于完成了向 64 位的迁移,并随着 Snow Leopard 的发布推出了解决并行编程问题的 Grand Central Dispatch(简称 GCD)技术,释放了多核系统的潜力。
内核 64位化
读者应该发现,经过这 4 个发行版,Mac OS X 自下而上地对整个系统向 64 位迁移。10.3 内核空间提供了 64 位整数运算的支持。10.4 允许程序以 64 位模式运行在用户空间,并且提供了 64 位的 libSystem 使得开发者可以开发 64 位的 Unix 程序,而 10.5 中系统所有未废弃的函数库、框架都提供 64 位版本,到了 10.6,所有用户空间的程序,包括 Unix 层和图型界面层,基本都更新到 64 位。细心的读者不禁会问—那内核是 64 位的吗?是的,自下而上支持 64 位后,10.6 又从上往下,迁移了整个系统中最后一个也是最重要的部分—内核。
内核 64 位化的意义
对于 Windows、Linux,以及 FreeBSD 等操作系统,64位实现的第一步是实现 64 位的内核。然而 Mac OS X 却反其道而行。主要原因是,反正 32 位的内核也能以非模拟、非兼容的方式原生地运行 64 位用户空间程序,而内核和与内核动态链接的驱动,很少需要用到 64 位的寻址空间(你什么时候见过内核本身使用 4GB 内存?),所以该问题可以暂缓。
但要记住,用户空间的内存是由内核管理的,虚拟内存、内存分页等机制,都是由内核一一实现的。一旦在不久的将来,随着用户空间的内存占用越来越多,虚拟内存的分页比也会不断膨胀。比方说,一个用户程序使用 4GB 的空间,每个分页包含 4KB 的页面,那么总共有 1M 个页面。因此,假设一个页面需要 64B 的 PTE 来记录该页的位置,那总共也就需要 64MB 的内核空间来记录这个用户空间程序的虚拟内存,不算太多。而在不久的将来,如果一个 64 位用户程序使用 128GB 的空间,则需要 32M 个页面,每个页面 64B 的 PTE 会导致 2GB 的内核地址空间来寻址(暂不考虑大分页)。32 位的内核就显得非常紧张。
另外,上一期我们也提到 64 位的 Intel 架构提供了比 32 位多一倍的寄存器,因此,用户空间程序对 64 位内核的系统调用也会更快。根据苹果的数据,系统调用的响应速度比原先快了 250%,而用户空间和内核空间的数据交换也快了 70%,因此,64位内核要比 32 位内核更快。
-
- *苹果追求适当投资换取高回报的理想。
GCD(Grand Central Dispatch) 来临
很长一段时间以来,处理器靠更快的运行时钟来获得更高的效率。软件开发者无需改动或重新编译他们的代码,就能得到摩尔定律许诺他们的好处,因为处理器顺序地执行计算机指令,新一代的处理器就自动会跑得比原先更快。后来每每达到一个技术极限时,总有一些聪明的方法绕过这些极限,比如超纯量、指令管线化、快取等,不是悄无声息地把多条互相独立的指令同时运行,就是隐藏掉数据读写的延时
传统的并发编程模式,就是学习使用线程和锁。这听起来很简单,几句话能说明白:
● 把每个任务独立成一个线程;
●不允许两个线程同时改动某个变量,因此得把变量“锁”起来;
●手动管理线程的先后并发顺序和并发数量,让它们均匀地占满系统资源;
●最好系统中只有这个程序在运行,否则你精心设计好的线程管理算法往往不能达到原来该有的效果;
●最后祈祷程序在用户那儿不出问题。
但是实际操作起来,多线程程序的编写要比单线程难上不止一个数量级。一方面,调用大量内存和数据反复的加解锁本身效率就非常低下;另一个重要原因在于,由于多线程程序可能以任意的次序交错执行,程序再也无法像顺序执行时那样产生确定的结果。**多线程程序看似容易编写,但难分析、难调试,更容易出错。**即使是最熟练的开发者,在茫茫线程和锁之间,也会迷失方向。且程序的错误在很多时候甚至是不可重现的。所以,程序员使用线程和锁机制编写并行程序的代价是很高的。
GCD 就是在这种背景下被苹果提出来的。2008年最初提出但未公布细节时,很多人怀疑它是 FreeBSD 的 ULE 调度器在 Mac OS X 上的实现。GCD 的实现,实际上是依赖于 FreeBSD 的另一项技术 kqueue。kqueue 是一个由 FreeBSD 4 时代引入的新功能,内核级别地支持消息通信管理。GCD 的队列,其实就是用 kqueue 实现的。
GCD 出现的意义
在 GCD 中,开发者不再管理和创建线程,而是将要实现的运算抽象成一个个任务,一起扔给操作系统,转而让操作系统管理,这在计算机科学中,被称为线程池管理模式。
在 GCD 中,开发者使用很简单的方式就能描述清应用程序所需执行的任务,以及任务之间的相互关联。每一个任务在代码中被描述成块(block),然后开发者把一个一个块显式地按顺序扔到队列(queue)中。使用块和队列两个抽象的表述,开发者无须创建线程,也无须管理线程,更无须考虑数据的加解锁。换之而来的,是更简短可读的代码。剩下的事,全都扔给操作系统去完成。
在操作系统那边,GCD 在程序运行时,管理着一定数量的线程,线程的数量是自动分配的,取决于用户计算机的配置和用户程序运行时的负载。多核工作站每个程序配到的线程,自然就会比单核手机或双核笔记本来得多。而且这个线程的数量是会动态变化的。当程序非常忙时,线程数会相应增多,而当程序闲置时,系统会自动减少其线程数量。然后,GCD 会一一从队列中读入需要执行的块,然后扔到线程上并发执行。
相信读者已经看出 GCD 和传统线程-锁机制的区别来了。传统的方式按劳分配,强调程序自由独立地管理,妄想通过“无形的手”把系统资源平均分配,走的是资本主义市场经济的道路。而 GCD 按需分配,真正实现了社会主义计划经济管理模式。因此在政治上 GCD 就是一个代表先进生产力的计算机技术(我被自己雷了,但事实就是这样)。
GCD 是一个自底向上的技术,它实际上由以下 6 个部分组成。
- 编译器层面,LLVM 为 C、Objective-C 和 C++ 提供了块语法,这个内容等下会介绍。
- 运行库方面,有一个高效分配管理线程的运行库 libdispatch。
- 内核方面,主要基于 XNU 内核 Mach 部分提供的 Mach semaphores 和 BSD 部分提供的 kqueue () 机制。
- dispatch/dispatch.h 提供了丰富的底层编程接口。
- 在 Cocoa 层面,NSOperation 被重写,因为使用 libdispatch,所以先前使用 NSOperation 的程序不需改动,就自动享受 Grand Central Dispatch 的最新特性。
- Instruments 和 GDB 提供了非常完整的分析和调试工具。
GCD 还有一些工程上的优势。
首先,程序的响应速度会更快。比传统线程轻量的多,可以开成百上千个。
其次,线程模式是一种静态的模式,一旦程序被执行,其运行模式就被固定下来了。但用户的计算机配置各不相同,运行时别的程序有可能耗用大量的计算资源。这些都会影响该程序的运行效率。而动态分配系统资源则能很好地解决这个问题。
而最重要的,还是 GCD 采用的线程池模式极大简化了多线程编程,也降低了出错的可能性。
如何应用 GCD
首先是块状语法,是一个对 C、C++ 和 Objective-C 语言的扩展。用来描述一个任务,用^引导的大括号括起来。比如最简单的:
则 x 就变成了一个块。如果执行:
很多开发者亲切地称呼块语法的 C 扩展为“带 lambda 的C”。
有了闭包功能的 C 顿时牛起来——你可以把函数和数据包装在一起——这就是块的真正功能。因为只要一个闭包包含了代码和数据,它的数据就不会被别的闭包轻易改动,所以在它执行时,你根本不用为数据上锁解锁。
一旦队列不是空的,GCD 就开始分配任务到线程中。拿上面的例子来说,“老婆”、“城”等变量可是封在闭包里的,所以在运行时,不用考虑它们被某个别的闭包改掉(当然也有方法来实现这个功能)。总体而言,这个模式比线程-锁模型简单太多——它的执行是并行的,但思维却是传统的异步思维,对没有学习过系统多线程编程的开发者来说,依然能很容易地掌握。
GCD 在 Mac OS X 10.6 发布后,又以 libdispatch 为名,作为一个独立的开源项目发布。 所需的外围代码,如编译器的块支持、运行库的块支持、内核的支持,也都能在 LLVM 和 XNU 等开源项目代码中找到,所以很快被别的操作系统采用。作为 Mac OS X 的近亲, FreeBSD 在一个月后即完整移植了整套 GCD 技术,并最终在 FreeBSD 9.0 和 8.1 中出现。诸多 Linux 发行版也提供 libdispatch 的包,使用 Linux 内核的 epoll 来模拟 FreeBSD 的 kqueue。2011年 5 月 5 日, Windows 的移植工作也宣告完成。
另外,GCD 也成为拯救动态语言的重要法宝。由于受 GIL(全局解释锁)的限制,动态语言虽然有操作系统原生线程,但不能在多核处理器上并行执行。而 GCD 成功绕开了这个限制,如加入 GCD 支持的 Ruby 实现 MacRuby 就能在多核处理器上高效执行。 因此,在苹果生态圈以外,GCD 也会得到越来越多的应用。
OpenCL 诞生
OpenCL 则是苹果为这个新局面画下的蓝图。这项技术初期全称为 Open Computing Library(如果留意苹果早期宣传广告的话),后改名为 Open Computing Language。这项技术从本质上来说,和 CUDA 并没有太多的两样,但由于苹果在借鉴他人技术并把他人技术改得更棒这一点上是出了名的,所以 OpenCL 很好地解决了以上所有问题。
下面简单介绍一下这个框架。OpenCL 技术的结构十分清晰,对程序员来说,它是一个 Mac OS X 的 Framework,定义了两套标准,一套是一个 C 语言的编程界面(API),使得开发者创建、拷贝、回收 GPU 使用的对象,同时也包含检测处理器、为该处理器编译并调用核心程序(kernel)相关的接口;另一套是 OpenCL 核心程序语言的定义,是一套基于 C99 发展而来的语言。
Mac OS X 许多的底层库也使用 OpenCL 重写,如 Core Image,本身也是一个 GPU 加速库,使用 OpenCL 后相比原来,依然获得了可观的性能提升。
Snow Leopard 的发布标志着第一个 OpenCL 框架的完整实现,OpenCL 成为业界标准后,AMD 和NVIDIA 抛弃了原先的策略,投入开放标准的怀抱.
开发者的瓶颈
而且由于硬件的限制(显卡不支持指针运算),很多 C 的标准并未在 OpenCL 中出现,写链表还需要用整数去模拟地址。程序员需要手动管理内存,处理底层的核心调用以及数据读写。而显卡厂商也大多不愿公开 GPU 的技术细节.只能凭经验操作.
显卡作为系统最为重要的共享资源之一,不像现代操作系统那样提供内存保护机制,因此一个用户 OpenCL 程序的错误很容易导致整个计算机崩溃
APFS 文件系统
昙花一现的ZFS系统,面向的是大企业用户和机械磁盘优化,不在符合Apple的商业模式
干脆自己搞一个专为闪存,固态存储优化的文件管理系统APFS。